
self hosted
Journaux liées à cette note :
Certification HDS : ce que j'ai appris en creusant pour un ami
Un ami, professionnel libéral de santé, a vibe codé une application de gestion pour ses patients actuellement hébergée sur Supabase. Il souhaite migrer vers un Hébergeur de Données de Santé — il a notamment vu que Scaleway propose des services certifiés HDS — et m'a demandé si je connaissais un développeur pour l'accompagner dans ce projet.
J'ai croisé la notion de HDS pour la première fois en 2016, chez Tech-Angels. Depuis, j'ai suivi le sujet de loin sans jamais creuser.
Je profite de sa demande pour étudier le sujet en profondeur avant de lui répondre, et publier une note de ce que j'aurai appris.
Hébergeur de Données de Santé, c'est quoi ?
Toute personne physique ou morale qui héberge des données de santé à caractère personnel recueillies à l’occasion d’activités de prévention, de diagnostic, de soins ou de suivi médico-social pour le compte de personnes physiques ou morales à l'origine de la production ou du recueil de ces données ou pour le compte du patient lui-même, doit être agréée ou certifiée à cet effet.
Texte de loi : article L.1111-8 du Code de la santé publique
Qu'est-ce qu'une donnée de santé (DDS) ?
Avant d'aller plus loin, j'ai eu besoin de comprendre précisément ce qu'est une "donnée de santé".
La CNIL distingue trois catégories (source) :
- Les données de santé par nature : antécédents médicaux, diagnostics, traitements, résultats d'examens, ordonnances, comptes-rendus d'hospitalisation.
- Les données qui deviennent des données de santé par croisement : le poids ou le nombre de pas seuls ne le sont pas, mais croisés avec d'autres mesures (tension artérielle, apports caloriques), ils le deviennent.
- Les données qui deviennent des données de santé par leur usage : un rendez-vous chez un médecin, à lui seul, n'est pas une donnée de santé — mais le motif de la consultation, si.
Concrètement, dans l'application de mon ami, cela inclut probablement les noms des patients, leurs comptes-rendus, leurs ordonnances, les notes de suivi, et potentiellement les créneaux de rendez-vous liés à des actes de soins. Ce n'est pas seulement la « base médicale » au sens strict — c'est tout ce qui, relié à une personne identifiée, révèle qu'elle a reçu ou consulté pour des soins.
Un document médical sans identifiant, est-ce encore une donnée de santé ?
Une question qui m'est tout de suite venue à l'esprit : un document médical sans identifiant — pas de nom, pas de numéro de patient — est-ce encore une donnée de santé ?
La réponse dépend de la possibilité de ré-identification. Si le document est véritablement anonymisé, qu'il n'existe aucun moyen raisonnable de le relier à une personne, alors ce n'est plus une donnée de santé à caractère personnel — ça sort du périmètre du RGPD et du HDS.
Mais en pratique, c'est très difficile de le rendre vraiment anonyme. Un diagnostic rare, une date de traitement, ou un hôpital spécifique croisés avec d'autres sources, peuvent permettre de ré-identifier la personne.
La CNIL considère qu'une donnée est « personnelle » dès qu'il existe des « moyens raisonnablement susceptibles » de ré-identification.
Je pense qu'une bonne méthode pour estimer si c'est une DDS ou non, est de se mettre dans la peau d'un détective privé : si on me donnait ce document et tous les indices disponibles (date, hôpital, pathologie rare…), est-ce que je pourrais remonter à la personne ? Si la réponse est oui, c'est une donnée de santé. La question n'est donc pas « y a-t-il un nom dans le document ? » mais « quelqu'un, avec les moyens raisonnables, pourrait-il retrouver à qui ça appartient ? ».
Quels liens entre PII et DDS ?
Pour faire le lien avec les PII : toute Données de santé (DDS) est une PII, mais l'inverse n'est pas vrai. Un nom, une adresse email ou une adresse IP sont des PII parce qu'ils permettent d'identifier une personne.
Une donnée de santé est une PII qui révèle en plus quelque chose sur l'état de santé de cette personne. La distinction importe parce que le régime juridique n'est pas le même : les DDS sont soumises au RGPD comme les PII, mais avec des protections supplémentaires — secret médical, consentement explicite, obligation d'hébergement certifié HDS.
Qui est le "responsable de traitement" ?
Pour comprendre à qui s'applique la certification HDS, j'ai eu besoin de creuser la notion de "responsable de traitement" au sens du RGPD. Je croise ce terme régulièrement, je pense le comprendre dans les grandes lignes, mais j'ai voulu comprendre précisément où se situent les frontières.
D'après ce que j'ai compris, le responsable de traitement est la personne morale (ou la personne physique en entreprise individuelle) qui décide quoi faire avec les données personnelles. C'est elle qui détermine pourquoi on collecte les données et comment on les traite. Ce n'est pas l'individu (le médecin, l'infirmière) — c'est la structure juridique qui a la relation de soin avec le patient.
Concrètement :
| Situation | Responsable de traitement | Pourquoi ? |
|---|---|---|
| Médecin salarié à l'hôpital | L'hôpital (personne morale) | C'est l'hôpital qui a la relation avec le patient, pas le médecin individuellement |
| Médecin dans un cabinet en SARL | La SARL (personne morale) | C'est la SARL qui signe les contrats et est responsable en cas de fuite |
| Médecin libéral en entreprise individuelle | Le médecin (personne physique) | Il n'y a pas de structure intermédiaire |
| Cabinet médical | Le cabinet (personne morale) | Le cabinet détermine les règles de gestion du système d'information |
| Doctolib | Non — c'est un sous-traitant | Doctolib est un moyen de communication entre le médecin et le patient, comme un téléphone amélioré |
| Scaleway | Non — c'est un hébergeur | Scaleway fournit l'infrastructure, il ne traite pas les données pour ses propres fins |
| Un développeur freelance qui maintient le serveur | Non — c'est un sous-traitant | Il administre l'infrastructure pour le compte du responsable de traitement |
Cette distinction est cruciale pour comprendre la certification HDS. La loi dit que l'hébergement doit être certifié quand il est fait "pour le compte de" un responsable de traitement. Si tu es toi-même le responsable de traitement, tu n'héberges pas pour un tiers — tu héberges pour toi-même alors pas besoin de certification HDS (mais tu restes soumis au RGPD).
C'est pour ça qu'un médecin qui gère son propre dossier patient n'a pas besoin de HDS, mais qu'un hébergeur qui stocke les données pour le compte de ce médecin doit être certifié.
Un cas limite : les services médicaux numériques
Le cas des services médicaux numériques comme Poppins — "le dispositif médical numérique à domicile pour les enfants dyslexiques" — est compliqué. Qui est le responsable de traitement ?
La réponse dépend de qui décide quoi faire avec les données :
- Si Poppins décide quelles données collecter et comment les utiliser (recherche, amélioration du produit) alors Poppins est responsable de traitement
- Si l'orthophoniste décide quelles données utiliser pour le suivi du patient alors l'orthophoniste est responsable de traitement
- Si les deux ont un rôle de décision → co-responsabilité (article 26 RGPD)
Où est la documentation officielle HDS ?
La documentation officielle est trouvable sur le site https://esante.gouv.fr/ => "Produits et services" => "HDS" => "Les référentiels de la procédure de certification".
La documentation HDS est nommée "référentiel de certifications HDS", elle est disponible au format PDF à cette adresse https://esante.gouv.fr/sites/default/files/media_entity/documents/referentiel_certification_hds---fr--v2.pdf.
Je n'ai pas trouvé de version HTML de ce document.
D'après ce que j'ai compris, ce sont des personnes de l'Agence du Numérique en Santé (ANS) qui ont rédigé les 29 pages du référentiel de certifications HDS.
Ce référentiel a été officialisé dans le Journal Officiel le 16 mai 2024 https://www.legifrance.gouv.fr/jorf/id/JORFTEXT000049537692 par un ministre délégué à la santé. Ce document remplace la version précédente de 2018.
Et voici le communiqué de presse de l'ANS : Publication au Journal Officiel du référentiel de certification HDS : souveraineté des données et améliorations du référentiel.
Je suis ravi de lire la section Focus sur l’ajout d’exigences relatives à la souveraineté des données qui indique :
L’hébergement physique des données de santé doit être réalisé exclusivement sur le territoire d’un pays situé au sein de l’Espace Economique Européen.
🙂
Les 6 activités du référentiel HDS
Est considérée comme une activité d'hébergement de données de santé à caractère personnel sur support numérique ... des activités suivantes :
- La mise à disposition et le maintien en condition opérationnelle de sites physiques permettant d'héberger l'infrastructure matérielle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure matérielle du système d'information utilisé pour le traitement de données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure virtuelle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de la plateforme d'hébergement d'applications du système d'information ;
- L'administration et l'exploitation du système d'information contenant les données de santé ;
- La sauvegarde des données de santé
Cette liste, reformulée en activités concrètes :
| # | Activité |
|---|---|
| 1 | Gestion des sites physiques : datacenters, baies serveurs, climatisation, alimentation électrique, sécurité des locaux |
| 2 | Gestion de l'infrastructure matérielle : serveurs physiques, stockage, câblage réseau, commutation |
| 3 | Gestion de l'infrastructure virtuelle : machines virtuelles, réseaux virtuels, stockage virtuel, hyperviseurs |
| 4 | Gestion de la plateforme applicative : bases de données managées, conteneurs, serveurs d'application |
| 5 | Gestion des sauvegardes : sauvegardes automatisées, stockage hors site, restauration |
| 6 | Administration et exploitation du SI : supervision, mises à jour, gestion des accès, support technique, astreinte |
Il y a un point important que j'ai mis du temps à saisir : l'obligation de certification ne s'applique qu'à l'hébergement de données de santé pour un tiers qui est responsable de traitement.
Par conséquent, un professionnel de santé qui auto-héberge ses propres données n'a pas besoin de certification HDS pour les activités de cette liste qu'il administre lui-même.
Un exemple concret
Imaginons un cabinet de médecin, qui développe une application web qui contient des données de santé. Cette application est à destination de ses utilisateurs finaux, ses patients.
L'application web est codée en JavaScript avec PostgreSQL pour la persistance des données.
Pour le déploiement, le développeur employé directement par le cabinet de médecin fait le choix de déployer le tout sur une Virtual machine Scaleway.
D'après la version du 18 juin 2026 de la page "L’hébergement des données de santé et la certification HDS" de la documentation Scaleway, voici la liste des services certifiés HDS :

Les composants de fondations les plus importants sont bien certifiés. Je note au passage que l'offre "Managed Database for PostgreSQL and MySQL" n'est pas certifiée pour le moment.
Ceci n'est pas grave dans mon exemple si je déploie directement une image Docker de PostgreSQL directement sur la Virtual machine. Les sauvegardes peuvent être déposées dans Scaleway Object Storage qui lui est certifié.
Le cabinet de médecin devra souscrire un plan de support niveau Business à 250 € par mois pour pouvoir ensuite signer un contrat HDS :

Ensuite, Scaleway remettra au cabinet de médecin (son client) un document de garantie HDS, conformément au chapitre 8 du référentiel :
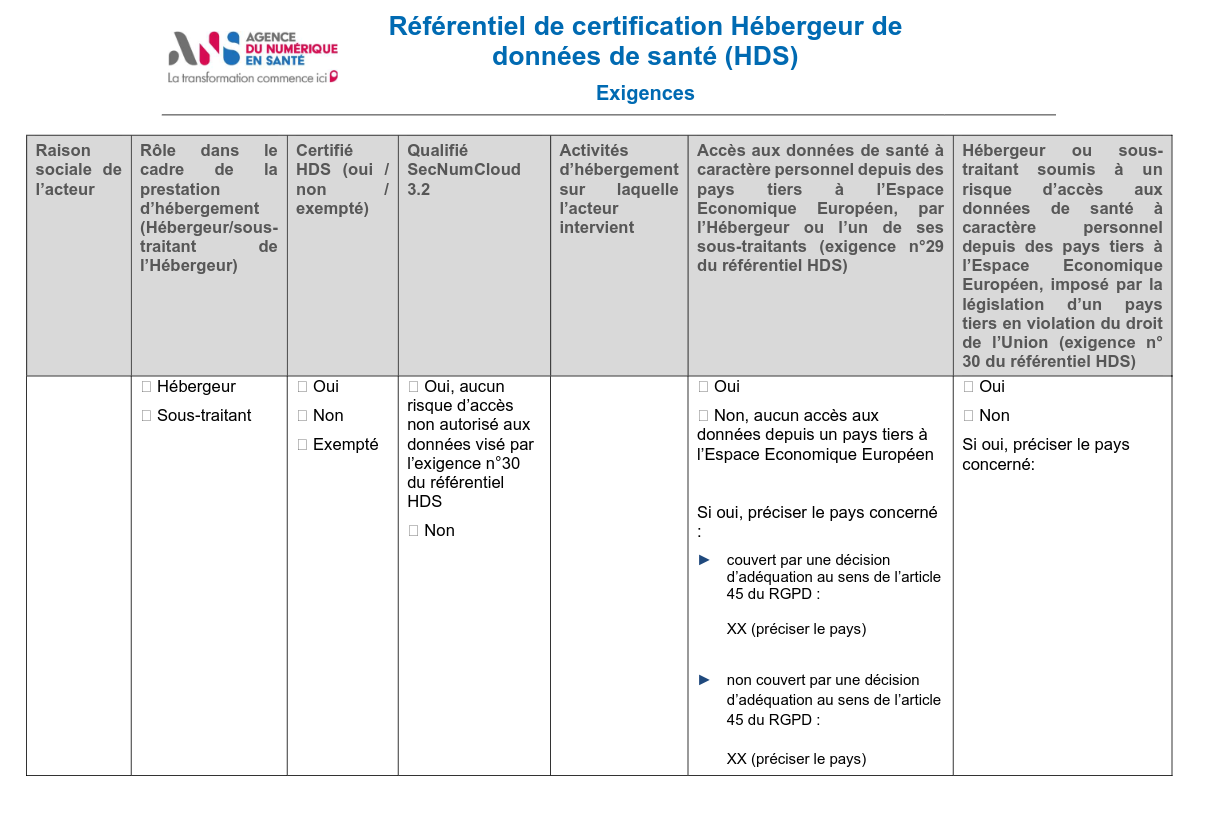
Voici à quoi pourrait ressembler ce document : "Exemple fictif d'une garantie de certification HDS de Scaleway".
Ensuite, les DevOps salariés directement du cabinet de santé déploient, maintiennent, administrent l'application sur les Virtual machine de Scaleway sans que le cabinet de médecin n'ait besoin de certification HDS car il n'est pas un hébergeur de données parce qu'il ne vend pas son service à d'autres professionnels. Seuls les patients directs utilisent son service.
Employé vs freelance : une distinction absurde mais légale
Il y a un point que j'ai mis du temps à saisir, et qui me paraît absurde mais qui est juridiquement cohérent.
Un employé (CDD ou CDI) du cabinet de santé qui gère le serveur, fait les mises à jour et les sauvegardes n'a pas besoin de certification HDS. Il fait partie de l'organisation du responsable de traitement — il n'est pas un sous-traitant.
Le même développeur, faisant exactement le même travail (SSH, mises à jour, sauvegardes), mais en freelance vendant 5 heures de prestation, a besoin de la certification HDS pour l'activité 5 (administration et exploitation). Pourquoi ? Parce qu'il est une entité séparée, un sous-traitant au sens RGPD, qui assure une activité d'hébergement pour le compte d'un tiers responsable de traitement.
La distinction ne se fait pas sur la nature du travail, mais sur le statut juridique de la personne qui le fait :
- Employé du cabinet (CDD/CDI) avec accès SSH → pas de HDS, il fait partie du responsable de traitement
- Freelance avec accès SSH permanent → HDS requis, il est sous-traitant et assure l'activité 5
Le cas du freelance qui livrerait uniquement du code
Si le freelance se contente de fournir du code — application, scripts d'infrastructure, configs de déploiement — et qu'il push tout dans un repo Git sans jamais avoir accès au serveur, à la base de données ni aux données, alors il n'assure aucune des 6 activités d'hébergement. Il livre un produit (du code), il n'opère pas un service.
Le test légal reste le même : "le fait d'assurer pour le compte du responsable de traitement tout ou partie des activités suivantes." Le verbe clé est "assurer" — c'est-à-dire exécuter, opérer, maintenir en condition opérationnelle. Les 6 activités décrivent des opérations sur l'infrastructure et le système, pas de la production de code.
La frontière se joue sur un point précis : qui appuie sur le bouton "déployer" ?
- Si c'est un employé du cabinet de santé qui contrôle l'outil de déploiement (par exemple ArgoCD) et déclenche les déploiements → freelance = livreur de code → pas de HDS
- Si le freelance a accès à cet outil et déclenche lui-même les déploiements → il participe à l'exploitation (activité 5) → HDS requis
Combien coûte une certification HDS pour les activités 4, 5 et 6 ?
J'ai cherché le processus officiel pour obtenir la certification HDS, voici ce que j'ai retenu :
- Mettre en place un Système de Management de la Sécurité de l'Information (SMSI) conforme à ISO 27001 (politique de sécurité, analyse de risques, gestion des accès, plan de continuité) — prérequis obligatoire.
- Choisir un organisme certificateur accrédité Comité français d'accréditation (Cofrac) (BSI, AFNOR, Bureau Veritas, LRQA…).
- Audit sur site en deux volets : conformité ISO 27001, puis exigences HDS spécifiques.
- Correction des non-conformités relevées.
- Obtention du certificat (valable 3 ans, avec audit de surveillance annuel).
J'ai volontairement laissé de côté le contenu concret du SMSI et de la norme ISO 27001 — je les connais mal. Cette note m'a donné envie d'explorer le sujet en profondeur, mais je le ferai dans une note séparée pour ne pas allonger encore celle-ci.
Les coûts typiques pour une TPE (< 10 personnes) :
| Poste | Estimation |
|---|---|
| Mise en place SMSI (conseil externe) | 2 000 – 6 000 € |
| Audit initial COFRAC (ISO 27001 + HDS) | 8 000 – 15 000 € |
| Audits de surveillance annuels (×2) | 2 000 – 5 000 € |
| Sous-total coûts externes | 12 000 – 26 000 € |
| Coût interne du salarié (100 – 200 h à 500 €/j soit ~70 €/h super brut) | 7 000 – 14 000 € |
| Total sur 3 ans | 19 000 – 40 000 € |
Estimation en temps humain (pour une personne seule, en charge de tout) :
| Étape | Effort humain estimé | Durée calendrier estimée |
|---|---|---|
| Mise en place SMSI (rédaction, procédures, analyse de risques, choix des outils) | 40 – 100 heures | 2 – 4 mois |
| Choix du certificateur et préparation du dossier | 15 – 30 heures | 3 – 6 semaines |
| Audit initial (sur site + préparation) | 15 – 30 heures | 1 – 2 semaines |
| Correction des non-conformités | 20 – 60 heures | 2 – 6 semaines |
| Obtention du certificat + 1er audit de surveillance | 10 – 30 heures | 1 – 2 mois |
| Total (avec SMSI ou maturité existante) | 100 – 250 heures | 6 – 9 mois |
| Total (sans SMSI préalable) | 200 – 400 heures | 12 – 18 mois |
Sources
Les fourchettes de coûts et de durées ci-dessus sont des estimations de Fermi calculées par MiMO-V2-Pro, recalibrées pour coller aux données publiées :
- Legiscope — Certification HDS hébergeur de données de santé 2026 (Dr. Thiébaut Devergranne, 23 mai 2026) : fourchette de 20 000 à 35 000 € sur 3 ans pour une TPE. Durée de 6 à 9 mois si l'organisation dispose déjà d'un SMSI ou d'une maturité ISO 27001 ; 12 à 18 mois sans SMSI préalable (dont 9-12 mois pour la certification ISO 27001 seule).
- Galeon — Certification HDS en 2026 (21 avril 2026) : « Les audits représentent généralement plusieurs dizaines de milliers d'euros, auxquels s'ajoutent les coûts internes de préparation et de mise en conformité. »
Je pense que des outils de service d'automatisation de conformité du type Oneleet que j'ai testés, peuvent accélérer le processus de mise en place d'un SMSI pour obtenir une certification ISO 27001.
Le risque sécurité du code vibe codé
Ça me fait un peu peur, honnêtement. Mon ami a vibe codé une application qui contient des données de santé. Et payer les frais importants d'une agence de développeur certifiée HDS n'aurait aucun sens dans ce contexte d'une application amateur sur mesure.
Qu'est-ce que je vais répondre à mon ami ?
D'abord, son idée d'hébergement chez Scaleway va coûter cher ! Déjà 250 € par mois rien que pour le plan de support Business.
Pour éviter cela, une solution serait d'auto-héberger l'application chez soi, dans son bureau, sur un petit serveur. Tant qu'on n'héberge pas pour un tiers, il n'y a pas besoin de certification HDS.
Mais il ne pourra pas demander à un développeur freelance d'administrer ce serveur. Dès qu'un freelance intervient sur l'infrastructure (accès SSH, mises à jour, sauvegardes), il assure l'activité 5 du référentiel HDS — et il devrait être certifié ! Et le coût de la certification pour administrer ce serveur, pour une seule instance, sera bien trop élevé.
Autre solution : embaucher un développeur en CDD pour toute intervention. C'est légalement possible sans HDS, mais c'est lourd à gérer et coûteux.
Réflexion sur le Vibe coding : libération ou prolétarisation ?
En tant qu'artisan développeur, je trouve amusant d'observer plusieurs de mes amis vibe coder des applications sur mesure pour leur besoin.
Pour le moment je n'ai pas cherché à savoir s'ils essaient de comprendre le code produit, ou si le code reste une boîte noire dont ils se fichent tant que ça marche. Mais c'est un phénomène socialement intéressant, et je ne sais pas si c'est une bonne nouvelle ou non.
Si le vibe coding reste un outil d'appropriation, si la personne comprend ce qu'elle fait, peut modifier, adapter, expliquer — alors c'est un acte de déprolétarisation : il reprend le contrôle sur ses outils de travail.
Mais si le code reste opaque, s'il ne s'agit que de produire sans comprendre, alors le vibe coding n'est qu'une nouvelle forme de prolétarisation. Le savoir ne passe plus par la machine au sens de Bernard Stiegler — il passe par l'IA, et la personne reste aussi démunie que devant si l'outil disparaît ou change, c'est de la désindividuation au sens de Bernard Stiegler. La personne n'a pas acquis de savoir, elle a acquis un résultat, elle "consomme".
C'est ce qui fait de ces outils des pharmakons : ils peuvent désindividuer autant qu'ils peuvent aider à s'individuer, selon l'usage qu'on en fait.
J'ai développé cette réflexion dans "J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes" et dans "Ma lutte contre mon affaiblissement cognitif". En résumé, j'essaie personnellement d'éviter cette prolétarisation : plutôt que de consommer l'IA pour produire des choses, j'essaie de groker — comprendre en profondeur, pas seulement obtenir un résultat.
Journal du dimanche 16 novembre 2025 à 22:17
Suite à publication des notes "Setup Fedora CoreOS avec LUKS et TPM, non sécurisé contre le vol physique de serveur", "Setup Fedora CoreOS avec LUKS et Tang", j'ai réfléchi à mes prochaines itérations du Projet 34 - "Déployer un cluster k3s et Kubevirt sous CoreOS dans mon Homelab".
Je souhaite réaliser et publier un playground pour étudier et tester les solutions VPN suivantes :
- Tailscale (solution partiellement libre, opéré par une entreprise basée au Canada)
- netbird (solution totalement libre, qui propose une version SaaS opérée par une entreprise basée en Allemagne)
- headscale (solution totalement libre à self hosted)
Dans un premier temps, je souhaite pouvoir accéder en ssh aux serveurs de mon Homelab depuis n'importe où. L'objectif est d'utiliser une méthode unique pour me connecter à ces serveurs en utilisant simplement leur hostname, sans avoir à gérer leurs adresses IP locales ni à configurer manuellement des entrées DNS.
Je souhaite tester l'installation de ces solutions sur des serveurs sous CoreOS, ma workstation sous Fedora et sous Android.
Idéalement, je souhaite configurer les services netbird et Tailscale via Terraform.
Je ne pense pas tester tout le suite headscale.
Setup Fedora CoreOS avec LUKS et Tang
Il y a quelques jours, dans ma note "Setup Fedora CoreOS avec LUKS et TPM", je disais :
Une solution pour traiter ce point faible est d'utiliser un pin éloigné physiquement du serveur qui l'utilise.
Le framework Clevis utilise le terme "pins" pour désigner les différents méthodes de déverrouillage d'un volume LUKS.
Origine du mot "pin" ?
Claude Sonnet 4.5 m'a expliqué que le terme "pin", qui se traduit par "goupille" en français, désigne la pièce mécanique qui bloque l'ouverture d'un cadenat.
Par exemple, dans un contexte self hosting dans un homelab, je peux héberger physiquement un serveur dans mon logement et le connecter à un pin sur un serveur Scaleway ou sur un serveur dans le homelab d'un ami.
Les pins distants, accessibles via réseau, sont appelés serveurs Network-Bound Disk Encryption.
Si le serveur Network-Bound Disk Encryption est configuré pour répondre uniquement aux requêtes provenant de l'IP de mon réseau homelab, en cas de vol du serveur, le voleur ne pourra pas récupérer le secret permettant de déchiffrer le volume LUKS.
Dans le playground install-coreos-iso-on-qemu-with-luks-and-tang, j'ai testé avec succès le déverrouillage d'un volume LUKS avec un serveur Network-Bound Disk Encryption nommé tang.
Pour être précis, dans la configuration de ce playground, deux pins sont obligatoires pour déverrouiller automatiquement le volume : un pin tang et un pin TPM2. Le nombre minimum de pins requis pour le déverrouillage est défini par le paramètre threshold.
clevis, qui permet de configurer les pins et de gérer la récupération de la passphrase à partir des pins, utilise l'algorithme Shamir's secret sharing (SSS) pour répartir le secret à plusieurs endroits.
Voici quelques scénarios de conditions de déverrouillage que clevis permet de configurer grâce à SSS :
- TPM2 ou Tang serveur 1
- TPM2 et Tang serveur 1
- Tang serveur 1 ou Tang serveur 2
- 2 parmi Tang serveur 1, Tang serveur 2, Tang serveur 3
- ...
Si les conditions ne sont pas remplies, systemd-ask-password demande à l'utilisateur de saisir sa passphrase au clavier.
Je n'ai pas trouvé d'image docker officielle de tang. Toutefois, j'ai trouvé ici l'image non officielle padhihomelab/tang (son dépôt GitHub : https://github.com/padhi-homelab/docker_tang).
Dans mon playground, je l'ai déployé dans ce docker-compose.yml.
J'ai trouvé la configuration butane de tang simple à définir (lien vers le fichier) :
luks:
- name: var
device: /dev/disk/by-partlabel/var
wipe_volume: true
key_file:
inline: password
clevis:
tpm2: true
tang:
- url: "http://10.0.2.2:1234"
# $ docker compose exec tang jose jwk thp -i /db/pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw.jwk
# pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw
thumbprint: dx9dNzgs-DeXg0SCBQW5rb7WQkSIN1B8MIgcO6WxJfI
threshold: 2 # TMP2 + Tang (or passphrase keyboard input)
La seule complexité que j'ai rencontrée est la méthode pour récupérer le paramètre thumbprint de l'instance tang.
Voici la méthode que j'ai utilisée :
$ docker compose exec tang jose jwk thp -i /db/pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw.jwk
pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw
Autre difficulté, il faut ajouter les arguments kernel suivants pour activer l'accès réseau dès le début du process de boot afin de permettre à clevis d'accéder au serveur tang :
variant: fcos
version: 1.6.0
kernel_arguments:
should_exist:
- ip=dhcp
- rd.neednet=1
J'ai intégré au README.md du playground une section nommée "How to switch from 2 required ping to 1 or the opposite?", pour documenter comment modifier à chaud la configuration clevis.
Par exemple pour changer de serveur tang ou modifier le nombre de pins nécessaires pour déverrouiller la partition chiffrée.
Il est conseillé d'activer le pin TPM2 en complément de tang pour éviter ce type d'attaque décrit par Claude Sonnet 4.5 :
Imaginons un admin malveillant dans ton entreprise :
- Il a accès physique aux serveurs
- Il a accès au réseau (donc au serveur Tang)
- Il clone un disque pendant la nuit
- Il essaie de le monter sur sa propre machine pour extraire des données
Tang seul : ❌ Il réussit
TPM + Tang : ✅ Il échoue
À noter que l'instance tang ne contient pas la passphrase et ne voit jamais passer la passphrase via son API.
Voici les explications que m'a données Claude Sonnet 4.5 :
Tang ne stocke pas la passphrase secrète de chiffrement LUKS. C'est justement tout l'intérêt de cette solution !
Voici comment ça fonctionne :
Le principe de Tang + Clevis
- Génération de clé dérivée : Clevis (le client) contacte le serveur Tang et récupère sa clé publique
- Chiffrement avec la clé de Tang : Clevis utilise cette clé publique pour chiffrer la passphrase LUKS
- Stockage local : La passphrase chiffrée est stockée localement dans l'en-tête LUKS du disque (pas sur le serveur Tang)
- Déchiffrement au boot :
- La machine contacte Tang
- Tang utilise sa clé privée pour aider à déchiffrer
- La passphrase LUKS est reconstituée
- Le disque est déverrouillé
Ce que Tang sait et ne sait pas
- ❌ Tang ne connaît jamais votre passphrase LUKS
- ❌ Tang ne stocke rien concernant vos clés
- ✅ Tang fournit juste un service cryptographique (un oracle de déchiffrement)
- ✅ C'est un serveur sans état (stateless)
C'est du chiffrement asymétrique avec un mécanisme appelé "network-bound disk encryption" : le disque ne peut être déchiffré que si la machine peut contacter le serveur Tang sur le réseau.
Voici quelques ressources supplémentaires au sujet des techniques de déverrouillage automatique des volumes LUKS :
J'ai découvert Podman Quadlets
Dans ce thread du Subreddit self hosted, #JaiDécouvert Podman Quadlets, une fonctionnalité de podman.
D'après ce que j'ai compris, Podman Quadlets est un système qui permet de lancer des containers podman via systemd de manière déclarative.
Techniquement, Podman Quadlets transforme des fichiers .container en fichier unit files systemd classique.
Exemple d'un fichier .container :
# ~/.config/containers/systemd/nginx.container
[Unit]
Description=Nginx web server
After=network-online.target
[Container]
Image=docker.io/library/nginx:latest
PublishPort=8080:80
Volume=/srv/www:/usr/share/nginx/html:ro,Z
[Service]
Restart=always
[Install]
WantedBy=default.target
Et pour ensuite lancer ce container :
$ systemctl --user daemon-reload
$ systemctl --user start nginx
$ systemctl --user enable nginx
J'ai aussi découvert le projet podlet, (https://github.com/containers/podlet) qui permet de générer des fichiers Podman Quadlets à partir de fichiers docker compose.
J'apprécie que podman incarne la philosophie Unix en s'intégrant nativement aux composants Linux comme systemd, plutôt que de réinventer la roue comme Docker.
J'ai découvert l'outil de build Javascript avec cache remote nommé "nx"
En étudiant un projet privé professionnel, #JaiDécouvert le projet nx qui est comme Turborepo un outil de build pour Javascript et TypeScript.
Pour commencer, je dois préciser que je n'apprécie pas du tout comment le projet se présente. On voit partout :
Cela me donne l'impression que ce "pitch" a été créé par une équipe marketing 🙉 !
J'ai découvert ce tout petit thread Hacker News qui date du 18 août 2022 sur Hacker News qui, je trouve, explique très bien le but de Nx :
I'm a core team member of Nx (nx.dev) and one of the core features we implemented quite a while ago, is "computation caching". Basically to speed up things, we get all the input to a given computation, which our case as a devtool means running your Jest tests, Webpack/esbuild/... build etc, and cache the result (logs & potential build artifacts).
Next time when the same computation is run, we look it up and restore it from the cache, obviously tremendously improving the speed of the run. The real value is when you distribute that cache among co-workers, CI agents etc., which you can do with Nx Cloud (nx.app).
We had played with the idea of potentially mapping this to CO2 emissions. If you start saving a lot of computation, this reduces the number of times a machine gets spin up & executed on your CI. Well, earlier this week we aggregated some stats of how much time we saved and we were pretty by the result ourselves!
I summed it up in this blog article: https://blog.nrwl.io/helping-the-environment-by-saving-two-centuries-of-compute-time-feea8e1ce22?source=friends_link&sk=9b1259d0b171a7b95ebe95b3795660b5
But basically we saved:
- last 7 days: ~5 years of compute time
- last 30 days: ~23 years
- since beginning of Nx Cloud: ~200 years
Je pense que ces mesures font référence à ce qu'on peut voir dans ce screenshot :
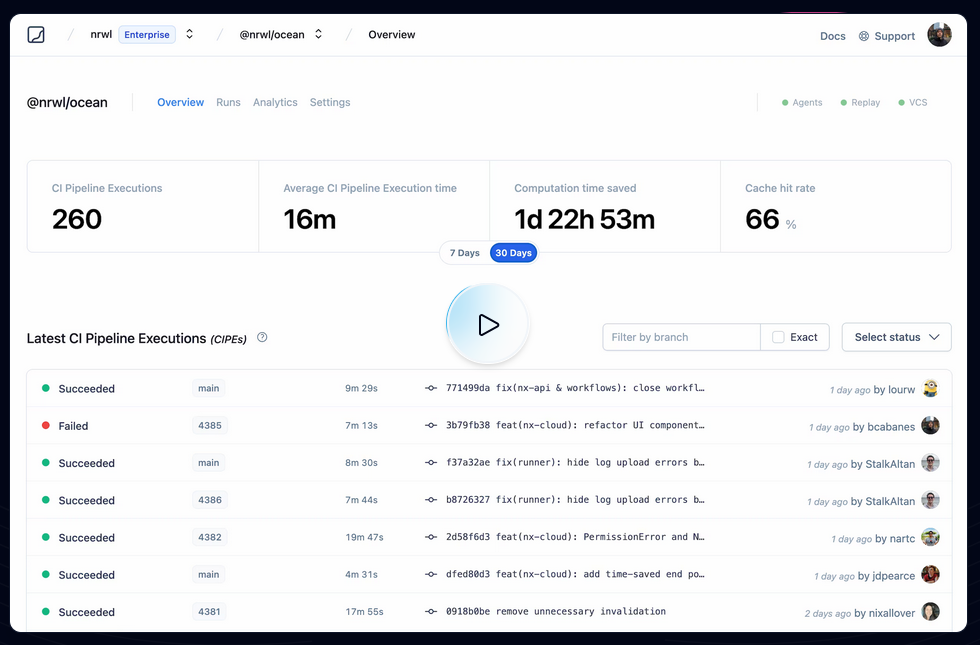
Je trouve cela très intéressant. Après avoir testé Bazel sans résultat concluant, sur la période 2018 à 2022, j'ai souvent cherché un outil comme Nx ou Turborepo, c'est-à-dire :
- Build distribué en parallèle sur différentes machines
- Partage de cache entre l'équipe de développement et les pipelines CI/CD
By default, Nx caches task results locally. The biggest benefit of caching comes from using remote caching in CI, where you can share the cache between different runs. Nx comes with a managed remote caching solution built on top of Nx Cloud.
To enable remote caching, connect your workspace to Nx Cloud by running the following command...
Je me demande si Nx permet de self host un composant de remote caching et si oui, je me demande si ce composant est open source ou non 🤔.
À noter que Turborepo permet de self host son propre service de remote cache : voir Turborepo - Remote Cache Self-hosting.
D'après mes recherches, Nx a été créé en juillet 2017, par Victor Savkin, un ancien développeur d'Angular chez Google. Selon cette description :
Software Engineer at Google (San Francisco Bay Area) between Jul 2014 - Dec 2016
One of the main developers of Angular 2. I've developed the dependency injection, change detection, forms, and router modules.
je pense que c'est pendant cette mission qu'il a eu l'idée de créer nx.
En janvier 2018, un second développeur Jason Jean, l'a rejoint sur le projet.
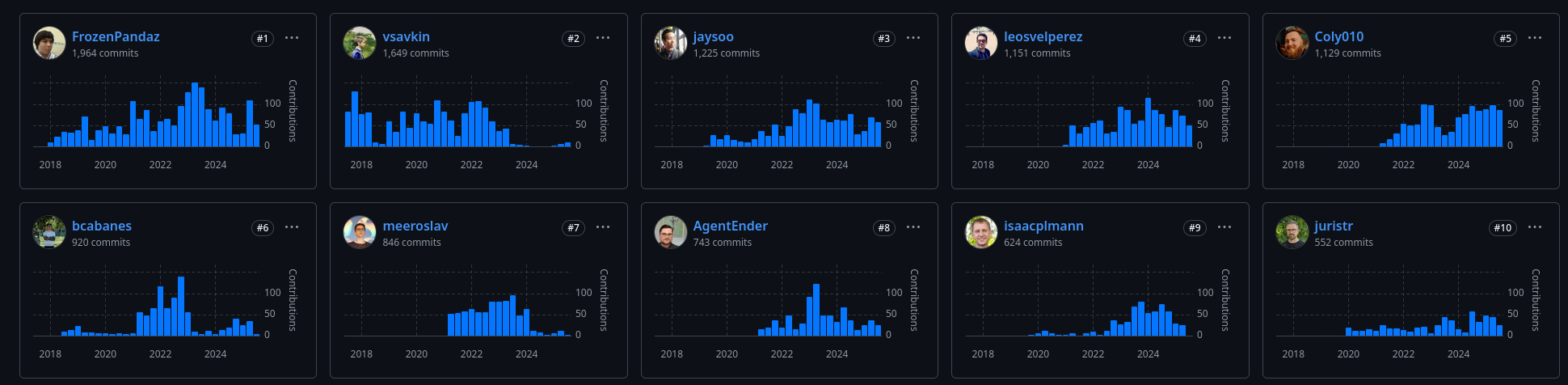
J'ai l'impression que Victor Savkin le CEO, n'a plus le temps de développer sur le projet depuis juillet 2023. Je pense que c'est à partir de là que le projet a eu de la traction.
Journal du mardi 25 février 2025 à 22:12
Un ami me demande :
Réponse courte : je pense qu'un NPU ne te sera d'aucune utilité pour exécuter un LLM de qualité sur ton laptop 😔.
Quand mon ami parle d'une « IA en local », je suppose qu'il souhaite exécuter un agent conversationnel qui exploite un LLM, du type ChatGPT, Claude.ai, LLaMa, DeepSeek, etc.
Sa motivation première est la confidentialité.
Cela fait depuis juin 2023 que je souhaite moi aussi self host un LLM, avant tout pour éviter le vendor locking, maitriser son coût et éviter la "la merdification des choses".
En juin 2024, je pensais moi aussi que les NPU étaient une solution technique pour self hosted un LLM. Mais depuis, j'ai compris que j'étais dans l'erreur.
Je trouve que ce commentaire résume aussi bien la fonction des NPU :
Also, people often mistake the reason for an NPU is "speed". That's not correct. The whole point of the NPU is rather to focus on low power consumption.
...
I have a sneaking suspicion that the real real reason for an NPU is marketing. "Oh look, NVDA is worth $3.3T - let's make sure we stick some AI stuff in our products too."
D'après ce que j'ai compris, voici ce que les NPU exécutent en local (ce qui inclut également la technologie Microsoft nommée Copilot) :
- L'accélération des modèles d'IA pour la reconnaissance vocale, la transcription en temps réel, et la traduction.
- Traitement plus rapide des images et vidéos pour des effets en direct (ex. flou d'arrière-plan, suppression du bruit audio).
- Réduction de la consommation électrique en exécutant certaines tâches IA en local, sans solliciter massivement le CPU/GPU.
Je pense que les fonctionnalités MS Windows Copilot qui utilisent des LLM sont exécutées sur des serveurs mutualisés avec de gros GPU.
Si j'ai bien compris, pour faire tourner efficacement un LLM en local, il est essentiel de disposer d'une grande quantité de RAM avec une bande passante élevée.
Par exemple :
- Une carte NVIDIA RTX 5090 avec 32Go de RAM (2700 €)
- Une carte NVIDIA RTX 3090 avec 24Go de RAM d'accasion (1000 €)
- Une Puce Apple M4 Max avec CPU 16 cœurs, GPU 40 cœurs et Neural Engine 16 cœurs 128 Go de mémoire unifiée (plus de 5000 €)
- Une Puce Apple M4 Pro avec CPU 12 cœurs, GPU 16 cœurs, Neural Engine 16 cœurs 64 Go de mémoire unifiée (2400 €)
Je ne suis pas disposé à investir une telle somme dans du matériel que je ne parviendrai probablement jamais à rentabiliser. À la place, il me semble plus raisonnable d'opter pour des Managed Inference Service tels que Replicate.com ou Scaleway Managed Inference.
Voici les tarifs de Scaleway Generative APIs :
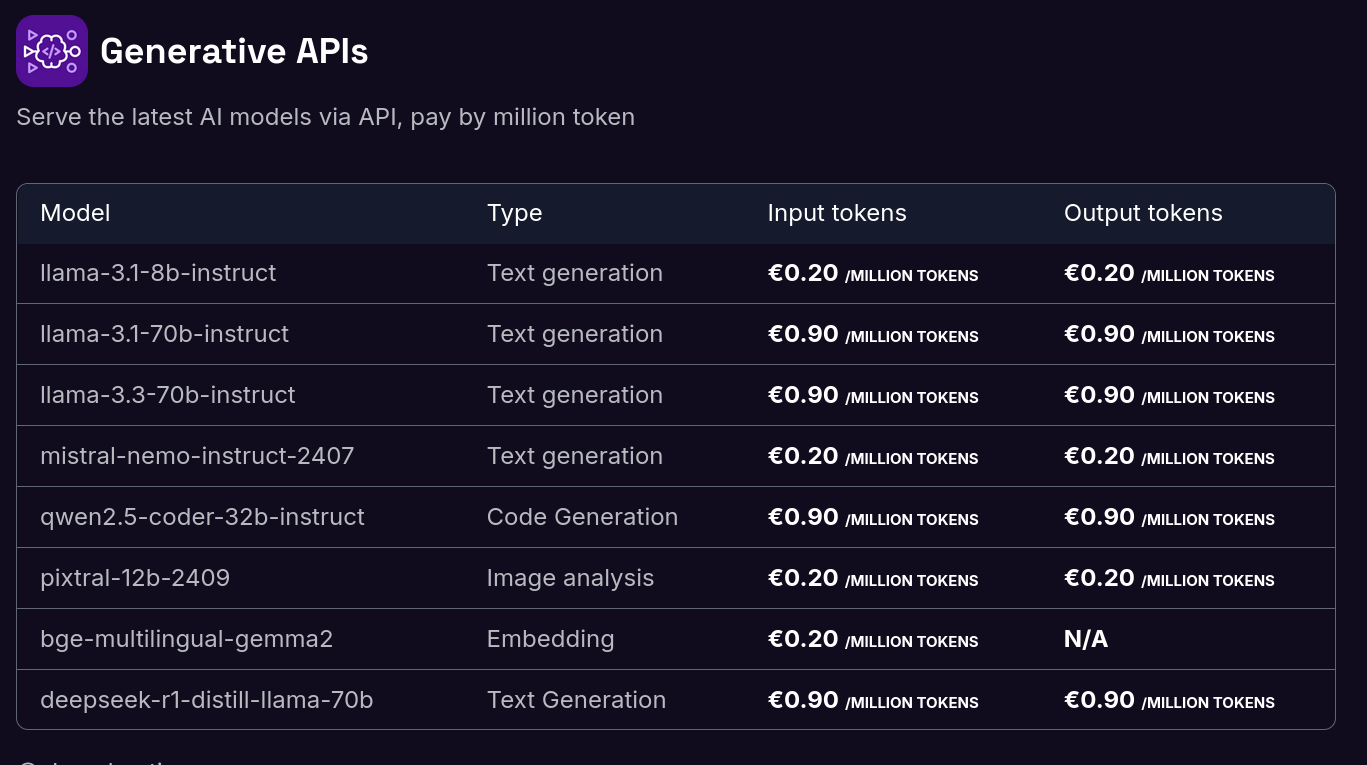
Il y a quelques semaines, j'ai connecté Open WebUI à l'API de Scaleway Managed Inference avec succès. Je pense que je vais utiliser cette solution sur le long terme.
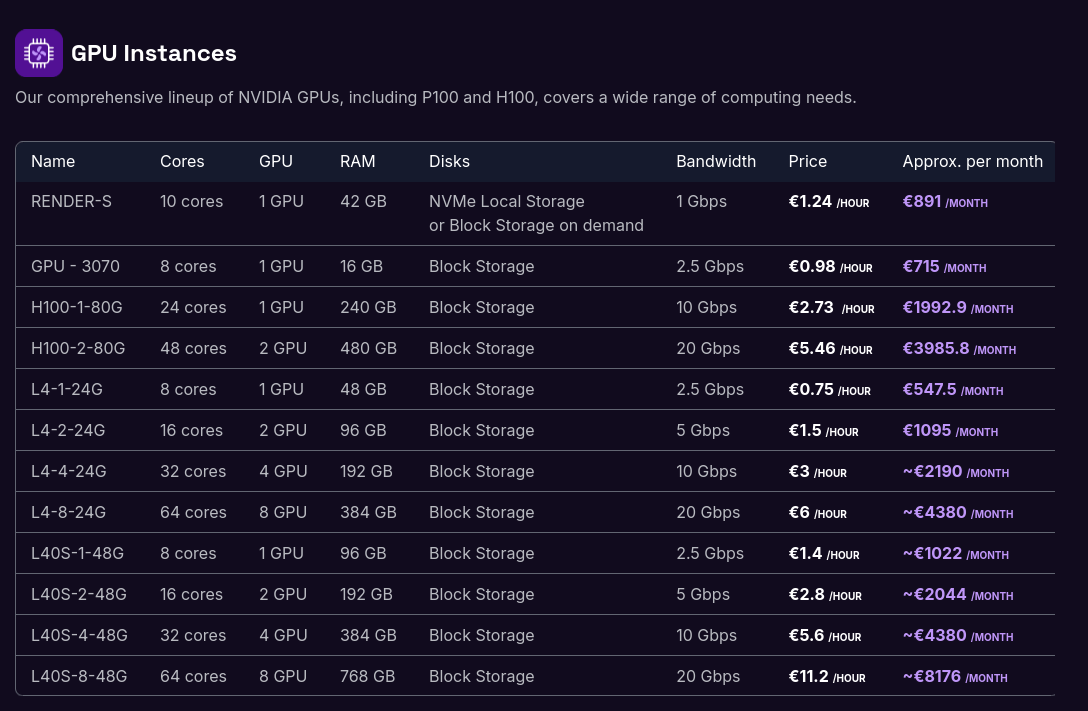
Si je devais garantir une confidentialité absolue dans un cadre professionnel, je déploierais Ollama sur un serveur dédié équipé d'un GPU :
Alternatives managées à ngrok Developer Preview
Dans la note 2024-12-31_1853, j'ai présenté sish-playground qui permet de self host sish.
Je souhaite maintenant lister des alternatives à ngrok qui proposent des services gérés.
Quand je parle d'alternative à ngrok, il est question uniquement de la fonctionnalité d'origine de ngrok en 2013 : exposer des serveurs web locaux (localhost) sur Internet via une URL publique. ngrok nomme désormais ce service "Developer Preview".
Offre managée de sish
Les développeurs de sish proposent un service managé à 2 € par mois.
Ce service permet l'utilisation de noms de domaine personnalisés : https://pico.sh/custom-domains#tunssh.
Test de la fonctionnalité "Developer Preview" de ngrok
J'ai commencé par créer un compte sur https://ngrok.com.
Ensuite, une fois connecté, la console web de ngrok m'invite à installer le client ngrok. Voici la méthode que j'ai suivie sur ma Fedora :
$ wget https://bin.equinox.io/c/bNyj1mQVY4c/ngrok-v3-stable-linux-amd64.tgz -O ~/Downloads/ngrok-v3-stable-linux-amd64.tgz
$ sudo tar -xvzf ~/Downloads/ngrok-v3-stable-linux-amd64.tgz -C /usr/local/bin
$ ngrok --help
ngrok version 3.19.0
$ ngrok config add-authtoken 2r....RN
$ ngrok http http://localhost:8080
ngrok (Ctrl+C to quit)
👋 Goodbye tunnels, hello Agent Endpoints: https://ngrok.com/r/aep
Session Status online
Account Stéphane Klein (Plan: Free)
Version 3.19.0
Region Europe (eu)
Web Interface http://127.0.0.1:4040
Forwarding https://2990-2a04-cec0-107a-ea02-74d7-2487-cc11-f4d2.ngrok-free.app -> http://localhost:8080
Connections ttl opn rt1 rt5 p50 p90
0 0 0.00 0.00 0.00 0.00
Cette fonctionnalité de ngrok est gratuite.
Toutefois, pour pouvoir utiliser un nom de domaine personnalisé, il est nécessaire de souscrire à l'offre "personal" à $8 par mois.
Test de la fonctionnalité Tunnel de Cloudflare
Pour exposer un service local sur Internet via une URL publique avec cloudflared, je pense qu'il faut suivre la documentation suivante : Create a locally-managed tunnel (CLI).
J'ai trouvé sur cette page, le package RPM pour installer cloudflared sous Fedora :
$ wget https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-x86_64.rpm -O /tmp/cloudflared-linux-x86_64.rpm
$ sudo rpm -i /tmp/cloudflared-linux-x86_64.rpm
$ cloudflared --version
cloudflared version 2024.12.2 (built 2024-12-19-1724 UTC)
Voici comment exposer un service local sur Internet via une URL publique avec cloudflared sans même créer un compte :
$ cloudflared tunnel --url http://localhost:8080
...
Requesting new quick Tunnel on trycloudflare.com...
Your quick Tunnel has been created! Visit it at (it may take some time to be reachable):
https://manufacturer-addressing-surgeon-tried.trycloudflare.com
Après cela, le service est exposé sur Internet sur l'URL suivante : https://manufacturer-addressing-surgeon-tried.trycloudflare.com.
Voici maintenant la méthode pour exposer un service sur un domaine spécifique.
Pour cela, il faut que le nom de domaine soit géré pour les serveurs DNS de cloudflare.
Au moment où j'écris cette note, c'est le cas pour mon domaine stephane-klein.info :
$ dig NS stephane-klein.info +short
ali.ns.cloudflare.com.
sri.ns.cloudflare.com.
Ensuite, il faut lancer :
$ cloudflared tunnel login
Cette commande ouvre un navigateur, ensuite il faut se connecter à cloudflare et sélectionner le nom de domaine à utiliser, dans mon cas j'ai sélectionné stephane-klein.info.
Ensuite, il faut créer un tunnel :
$ cloudflared tunnel create mytunnel
Tunnel credentials written to /home/stephane/.cloudflared/61b0e52f-13e3-4d57-b8da-6c28ff4e810b.json. …
La commande suivante, connecte le tunnel mytunnel au hostname mytunnel.stephane-klein.info :
$ cloudflared tunnel route dns mytunnel mytunnel.stephane-klein.info
2025-01-06T17:52:10Z INF Added CNAME mytunnel.stephane-klein.info which will route to this tunnel tunnelID=67db5943-1f16-4b4a-a307-e8ceeb01296c
Et, voici la commande pour exposer un service sur ce tunnel :
$ cloudflared tunnel --url http://localhost:8080 run mytunnel
Après cela, le service est exposé sur Internet sur l'URL suivante : https://mytunnel.stephane-klein.info.
Pour finir, voici comment détruire ce tunnel :
$ cloudflared tunnel delete mytunnel
J'ai essayé de trouver le prix de ce service, mais je n'ai pas trouvé. Je pense que ce service est gratuit, tout du moins jusqu'à un certain volume de transfert de données.
Journal du samedi 28 décembre 2024 à 17:10
Comme mentionné dans la note 2024-12-28_1621, j'ai implémenté un playground nommé powerdns-playground.
J'ai fait le triste constat de découvrir encore un projet (PowerDNS-Admin) qui ne supporte pas une "automated and unattended installation" 🫤.
PowerDNS-Admin ne permet pas de créer automatiquement un utilisateur admin.
Pour contourner cette limitation, j'ai implémenté un script configure_powerdns_admin.py qui permet de créer un utilisateur basé sur les variables d'environnement POWERDNS_ADMIN_USERNAME, POWERDNS_ADMIN_PASSWORD, POWERDNS_ADMIN_EMAIL.
Le script ./scripts/setup-powerdns-admin.sh se charge de copier le script Python dans le container powerdns-admin et de l'exécuter.
J'ai partagé ce script sur :
- le SubReddit self hosted : https://old.reddit.com/r/selfhosted/comments/1hocrjm/powerdnsadmin_a_python_script_for_automating_the/?
- et le Discord de PowerDNS-Admin : https://discord.com/channels/1088963190693576784/1088963191574376601/1322661412882874418
AWS RDS playground et fixe du problème pg_dumpall
En 2019, j'ai rencontré un problème lors de l'exécution de pg_dumpall sur une base de données PostgreSQL hébergée sur AWS RDS. À l'époque, ce problème était "la goutte d'eau" qui m'avait empressé de migrer de RDS vers une instance PostgreSQL self hosted avec une simple image Docker dans un docker-compose.yml, mais je digresse, ce n'est pas le sujet de cette note.
Aujourd'hui, j'ai fait face à nouveau à ce problème, mais cette fois, j'ai décidé de prendre le temps pour bien comprendre le problème et d'essayer de le traiter.
Pour cela, j'ai implémenté et publié un playground nommé rds-playground.
Je peux le dire maintenant, j'ai trouvé une solution à mon problème 🙂.
Ce playground contient :
- Un exemple de déploiement d'une base de données AWS RDS avec Terraform.
- Un script qui permet d'importer avec succès la base de données AWS RDS vers une instance locale de PostgreSQL, en incluant les rôles.
Au départ, je pensais que le problème venait d'un problème de configuration des rôles du côté de AWS RDS ou alors que je n'utilisais pas le bon user. J'ai ensuite compris que c'était une fausse piste.
J'ai ensuite découvert ce billet : "Using pg_dumpall with AWS RDS Postgres".
For those interested, RDS Postgres (by design) doesn't allow you to read
pg_authid, which was earlier necessary for pg_dumpall to work.
J'ai compris que pour exécuter un pg_dumpall sur une instance RDS, il est impératif d'utiliser l'option --no-role-passwords.
Autre subtilité : sur une instance RDS, le rôle SUPERUSER est attribué au rôle rlsadmin, tandis que cette option est supprimé du rôle postgres.
ALTER ROLE postgres WITH NOSUPERUSER INHERIT CREATEROLE
CREATEDB LOGIN NOREPLICATION NOBYPASSRLS VALID UNTIL 'infinity';
Par conséquent, j'ai décidé d'utiliser le même nom d'utilisateur superuser pour l'instance locale PostgreSQL :
services:
postgres:
image: postgres:13.15
environment:
POSTGRES_USER: rdsadmin
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
...
Pour aller plus loin, je vous invite à suivre le README.md de rds-playground.
Idée d'un outil de session recoding web minimaliste basé sur rrweb
Plus le temps passe, et plus le nombre de services présents dans les docker-compose.yaml de OpenReplay et Posthog augmente.
Je trouve ces services de plus en plus pénible à self hosted pour de petits besoins de session recording.
J'ai envie d'essayer de créer un "mini" service de session recording, basé sur rrweb, SvelteKit et KeyDB ou DragonflyDB.
Je pense que ce projet pourrait être minimaliste 🤔.
2024-09-14 : j'ai nommé ce projet gibbon-replay.